AI News
Unveiling Attention Sinks: The Functional Role of First-Token Focus in Stabilizing Large Language Models
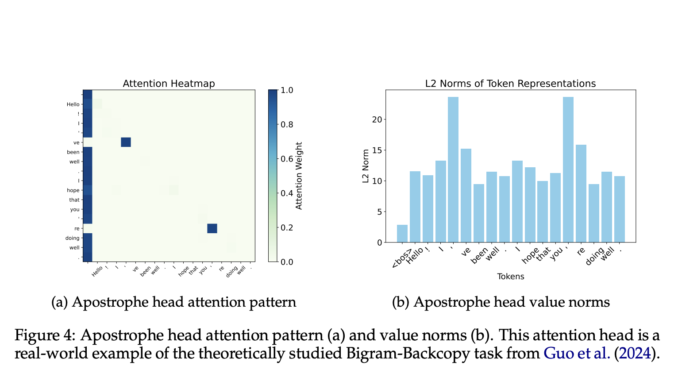
LLMs often show a peculiar behavior where the first token in a sequence draws unusually high attention—known as an “attention sink.” Despite seemingly unimportant, this token frequently dominates attention across many heads in Transformer models. […]